Advent of SQL Code, Week 2
Welcome to the second post about Advent of Code where I continue to look at all the puzzles through my relation model glasses and solve them using only SQL. Only SQL? Stick to the end of this post to find out. For days 1 to 6 see the previous post. The text on this page alone probably does not make much sense without the Advent of Code puzzles and my proposed solutions.
Day 7: Textbook Recursion
When we draw this task’s example, it could look like this:
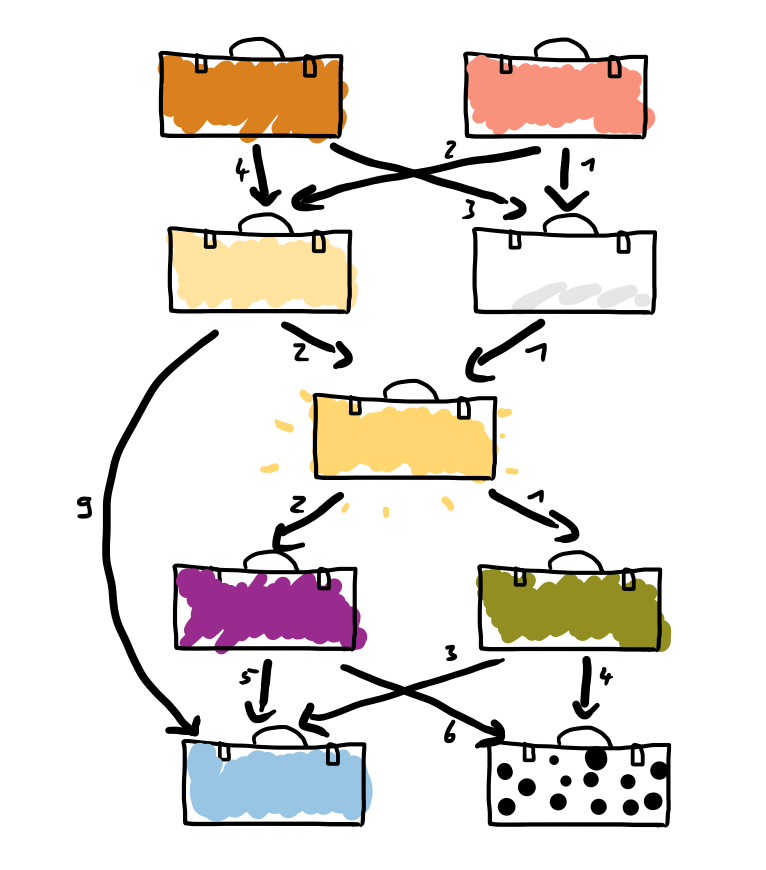
The arrows erase every bit of doubt that we are dealing with a directed graph here. And such quite explicit graphs are a textbook example for recursive queries where you start with some given set of nodes (bags) and dangle along the arrows to find what you are looking for.
For this task, I want to explain my process of getting to the right query. After loading the input, I first want to have a look at it:
select line from day7_bags_raw;
| line |
|---|
| muted coral bags contain 1 bright magenta bag, 1 dim aqua bag. |
| muted orange bags contain 2 bright red bags. |
| dim olive bags contain 2 dull silver bags, 4 posh blue bags. |
| … |
This is just every text line of the input, quite verbose. Each line’s start has the form blabla bags contain, and I am interested in the blabla part. Let’s see if I can extract this using substring and a regex:
select
substring(line, '(.*) bags contain') container
from day7_bags_raw;
| container |
|---|
| muted coral |
| muted orange |
| dim olive |
| … |
Great! But now I also need the rest of the line. Probably with a similar regex for the remainder?
select
substring(line, '(.*) bags contain') container,
substring(line, 'bags contain (.*)\.') containees
from day7_bags_raw;
| container | containees |
|---|---|
| muted coral | 1 bright magenta bag, 1 dim aqua bag |
| muted orange | 2 bright red bags |
| dim olive | 2 dull silver bags, 4 posh blue bags |
| … | … |
Ok, but these containees are not always one entry but could be more of them. Also, If only one bag is contained, then the plural-s is correctly omitted. Since multiple bags are always separated by a comma and a space, I convert each line to an array. Such NF$^2$ data can be normalized using unnest, where all other entries in this row are duplicated for each array value.
select
substring(line, '(.*) bags contain') container,
substring(
unnest(
string_to_array(
substring(line, 'bags contain (.*)\.'), ', '
)
),
'\d+ (.*)bags?'
) containees,
line
from day7_bags_raw
order by containees nulls first;
| container | containees | line |
|---|---|---|
| mirrored green | NULL | mirrored green bags contain no other bags. |
| muted coral | bright magenta | muted coral bags contain 1 bright magenta bag, 1 dim aqua bag. |
| muted coral | dim aqua | muted coral bags contain 1 bright magenta bag, 1 dim aqua bag. |
| muted orange | bright red | muted orange bags contain 2 bright red bags. |
| … | … | … |
I wanted to confirm that everything was going correctly, so I added the line-column to see the input of this substring-unnest-substring-move and ordered by its result. Indeed, there are some NULLs, but only for these bags containing no other bags, and I can happily live with that.
The query result resembles an adjacency list of the bag labels (colors), so I started with the graph-y part of the query and added the recursive frame.
with recursive rules as
(select
substring(line, '(.*) bags contain') container,
substring(
unnest(
string_to_array(
substring(line, 'bags contain (.*)\.'), ', '
)
),
'\d+ (.*) bags?'
) containee
from day7_bags_raw),
containments as(
select container, containee from rules where containee = 'shiny gold'
)
select * from containments;
| container | containee |
|---|---|
| light gold | shiny gold |
| dark tomato | shiny gold |
| … | … |
Writing the with recursive keyword does not force you to actually use recursion, but this looks like a good recursive base. Also, I figured that I matched a space too much (note the second space in \d+ (.*) bags?); hard to spot. And now all that was left is to add the recursion in order to get to each container’s container and so on, and finally count all these distinct containers.
with recursive rules as
(select
substring(line, '(.*) bags contain') container,
substring(
unnest(
string_to_array(
substring(line, 'bags contain (.*)\.'), ', '
)
),
'\d+ (.*) bags?'
) containee
from day7_bags_raw),
containments as(
select container, containee from rules where containee = 'shiny gold'
union all
select r.container, c.containee from containments c, rules r
where r.containee = c.container
)
select count(distinct container) from containments;
| count |
|---|
| 155 |
Part two is then derived from the previous solution. We are only walking in the other direction and carry the product of the weights of the paths with us.
Day 8
This advent continues to be super-cool! We are basically writing an interpreter for the handheld. I again go for recursion on that task, and just to reiterate why recursion is the perfect tool here: SQL recursion executes a query and unifies its result with the previous result until this union does not contain new elements. So my plan is to add a new step of the program in each iteration of the recursive evaluation. Once this step was already taken (the criterion for an endless loop in this riddle), the recursion automatically stops. If you want, the resulting table consists of a trace of the program.
Compared to Day 7’s riddle, we have a special kind of graph: a linear list. And the next element is derived depending on the instruction, the current program counter (i.e., the line number of the program), and, in the case of a jmp instruction, the argument. So don’t fear if your data does not immediately look like an adjacency list.
So we derive the next element in that list from the current tuple. And this is also how we can implement the swapping of an element which is needed for the second task.
Day 9
In the first task, we want combinations of two rows such that the numbers in these rows satisfy a particular property. Sounds like a join? Well, it is one. Using SQL, the first task is indeed pretty simple. The second task, however, forces you to create all kinds of subsets. And as always, when there’s no fixed number of elements we want to combine, this sounds like recursion. Like in day 4, this could also sound like window functions. However, with window functions (or even groupings), the predicates for defining the windows (groups) are not flexible enough.
Day 10
The first task is a little refreshing, it reminds me that not every result is relational in the sense of being a table, but it can also be just a scalar value. The second task here is much more challenging, though.
While the following works in theory, I stopped the following query after it required 30GB of temporary files on my disk and my window manager started behaving strangely.
with recursive sequences as (
select ARRAY[max(rating)] seq from day10_ratings
union
select rating || seq from sequences, day10_ratings
where rating > seq[1] - 4 and rating < seq[1]
)
select count(*) from sequences
where seq[1] >= 1 and seq[1] <= 3
With the example input with 31 lines, there’s no big problem; the query takes some milliseconds. However, the recursive query enumerates all the feasible sequences of adapters, which gets big quite quickly. In the following diagram, I run the query with the $n$ smallest ratings of my problem input.
And we see that until around 35 ratings, both the number of combinations (which are output by this query) and the runtime stay very manageable. But then both start increasing quite quickly. And for 50 ratings, runtime is already above 40 seconds, so I feel this quickly becomes unfeasible.
So instead of enumerating, we try to count the solutions. Here the idea is, if I want to know how many combinations I have for adapter with rating $r$, I look at the number of combinations for adapters $r-3$, $r-2$, $r-1$ (which I have computed beforehand). For $r$ the number of feasible combinations is the sum of the other adapters combinations. When I start this computation from an artificially inserted adapter with rating 0, I can get to the result rather quickly.
In theory, this sounds easy. However, in practice, I couldn’t get a query to work. For the query to start at 0 and continue until all adapters are handled, I need a recursive query. However, I could not formulate the query as I wanted. Windows cannot be defined over value ranges, recursive queries cannot contain group by’s, multiple joins with the working table, and the working table is also not allowed in a subquery. So, unfortunately, for this task, I had to resign and use plpgsql, which I would not consider being “only SQL.” Here you have it :).