Advent of SQL Code, Week 1
Advent of Code is an Advent calendar in form of a puzzle game. It’s on since 2015 and brings small programming tasks into your pre-Christmas period. I guess most people do this to learn a new programming language—which is a great idea—but for some reason, I decided to see how far I can get with just SQL. Please have a look at the puzzles by yourselves, I won’t repeat them here; I just want to share some SQL specific aspects which I think can be interesting to you. All my solutions are here on GitHub.
Day 1: Sums and Products
The puzzle input needs to be read somehow. For this I use postgres’ copy command which puts every line of a file into a new table row. After reading I have a single table with all the expenses.
Since the first part asks for a pair of entries, this calls for a self-join. Just a self join of table day1_expenses, select * from day1_expenses e1, day1_expenses e2 consists of all pairs of this table, including pairs of the same element (e.g., (6, 6)) and a pairs which contain the same elements but in flipped order (e.g., (3,8) and (8,3)). The last part is why I also filtered e1.expense < e2.expense, such that the result contains only a single row.
The second part searches for a triple of entries, which is basically a self-join with another self-join. While this might not be obvious from the query (select * from day1_expenses e1, day1_expenses e2, day1_expenses e3), postgres executes the query exactly like this, first a self-join, then another self join. You can visualize this for example using pgAdmin’s explain panel:
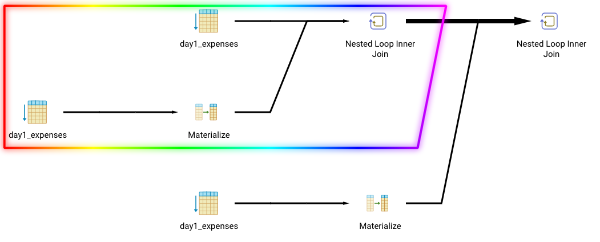
First the part in the decently marked box is executed and all tuples which leave this Nested Loop Inner Join operator go via that fat arrow into the next Join operator. The performance of these operators is sensitive to the size of inputs. But if we only use e1.expense + e2.expense + e3.expense = 2020, our database system can only check this, wenn the last join is also performed. So all possible $n\cdot n$ pairs leave the rainbowy box and make the outer inner join operator do much work. But we know, that all expenses are positive! This means, if we encounter a pair (1938, 582), the sum is bigger than 2020 and this will never be a part of the resulting expenses.
Byadding a filter like e1.expense + e2.expense <= 2020 which can be checked directly in the fairy-join operator, we can reduce this operator’s output and save the final join some time. How much time? On my system computing the query without that additional filter takes about 415ms, with the filter only 55ms!
Day 2: Passwords
For the passwords I added a little preprocessing and spent some quality time on the String Functions and Operators page. Here the idea is to translate the policy and password strings into separate columns of a table:
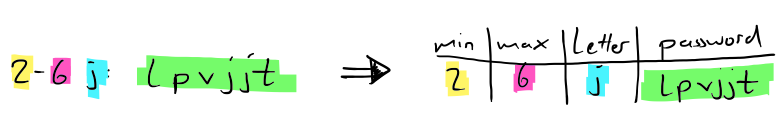
Then each row corresponds to the ingredients of a password policy and the password. And with the WHERE part of a query over this table, we can check each row if the password matches the policy. For this, we use the cool feature that regular expressions can use attributes of tuples, and replace all the characters in a password which are not the letter of the policy:
regexp_replace(password, '[^'||letter||']', '', 'g')
The second parameter to regexp_replace is the regular expression, and we construct this string (|| is postgres’ string concatenation) using the letter of the current row. For example, the password lpvjjt with the policy letter j is then transformed to jj, and the only thing left to do is to count the length of that transformed string and compare it to min and max.
Day 3: Sleigh Ride
The input files in the previous examples did not have an order. If you shuffle the lines and run the query, the result would be the same. But now, the lines need to be in order, or we cannot guarantee that we are counting the trees in the same order, the toboggan crashes into them. For this, I do not only read the line, but also add a serial field (id) to the table, so during reading the puzzle input, each line gets a new auto-incrementing number assigned.
For computing the position of the toboggan we need only the id value and we can exactly say how far from the left it will be positioned. So actually the order by-part I have in the code is unnecessary. However, I’d like to point out that just executing this inner query, is a great way of seeing what’s going on. As a tip for constructing SQL queries: select more attributes than you need, especially if you use these attributes somewhere else, e.g., in the where-clause or like here as parameters of other functions. This is also a good way in general to quickly find out, if indexes start at 0 or 1, or ranges are inclusive or exclusive (at least quicker than searching the documentation).
The second part of this sleigh ride asked for different slopes. While it would be possible to just copy and paste the previous query and alter the hard coded 3 into a 5 and so on, this is also a great potential to write a function. Postgres offers different languages for the procedure, but to keep it simple I just use SQL. This means, the function body is simply a query where I can use $1, $2 and so on as positional parameters.
Day 4: Passports
This. Is. Cool. The input file now not only has ordered lines, but also subsequent lines are grouped together. The validation part should be easy if we first get each of these groups into a single line, like this:

Just GROUP BYing won’t work, because we would need a common value which we don’t have. In theory, I would not completely dismiss custom window functions as an option, but I don’t see how the built-in ones could solve this problem. So, prepare for some recursion (pronounced fixed-point-i-ter-a-tion).
The mental model for recurive SQL queries is as follows: Start with something. Then explain how you can expand from that something. Expand until you don’t find anything new.
The start is the first line and every line that follows an empty line. We can check this like in the previous day using the id serial column, the non-first starting lines are these were the line with the next smaller id has a value of ''. For expanding, we go to the row with the next higher id unless its value is '' and append the row of the passport-string:

In the first iteration we just use the first row. The second iteration uses the result of the first iteration, and appends the passport fields of the second row. The third iteration uses the result of the second iteration and appends the passport fields of the third row, and the same for the next row.
In my solution, I do not only aggregate the passport fields into a long string, but also the ids into an array which I used for debugging. In fact, we could live without the latter, just use the id of the first row and pass it through the recursive part of the query. Which ever variant you use, you need to make sure to only report the final result, and not the intermediate ones.
The reminder of this day’s tasks are more fun with string operations, which is similar to the previous tasks. But hey, the recursion part was fun!
Day 5: Seat numbers
Seat numbers are cool, and you could probably 1:1 write the task description into some loops and branches computing the right value. But if you squint your eyes enough, you might see, that this is just another binary number system. So the approach is, to translate a string like FFBBFBF into another string like 0011010, and force the query engine to squint enough such that it interprets this as binary number. And presto, case solved.
And to add a little practical tip to this, such repeated nested function calls for converting strings sound like a good idea to create functions for this. This works not only with “SELECT-FROM-WHERE”-clauses, but also with just SELECT statmentes (queries without a table), and greatly improves readability.
Day 6: Customs
We learned on Day 4 how to use recusrive queries to group consecutive lines together. Cool. But now, we’ll use more arrays and mix arrays (multiple values in a row) and tables (multiple values in a column). The basic idea is to place letters into an array. For example, on the left the string in the puzzle file and on the right the letters in arrays.
msw --> {'m','s','w'}
xm --> {'x','m'}
jhmlr --> {'j','h','m','l','r'}
For the two parts of that day I had to approaches. For the first task, I concatenated the strings into a long string for each group. Then I unnested these arrays which basically transforms one row with an array of three entries to three rows with one entry each, like this:
| id | answered |
|---|---|
| 1 | {'m','s','w'} |
becomes
| id | answered |
|---|---|
| 1 | 'm' |
| 1 | 's' |
| 1 | 'w' |
And so, with a combination of GROUP BY id and COUNT(DISTINCT answered) we find the answer to this.
For the second task, this approach does not work because we lose the ability to find out if an answer was indeed given by all members of a group. This could maybe be done with counting (if an answer was given as often as the group has members, it is correct), however, we would need to eliminate duplicate answers earlier. Instead I altered the iteration part of the recursive query and in each step I only let these letters which were already peresent in the previous step. This sounds easy, but writing such an array intersection in SQL is letter intensive:
ARRAY(SELECT UNNEST(arr1) INTERSECT SELECT UNNEST(arr2))
For computing the intersection of two arrays arr1 and arr2, we first unnest them, so we treat them like tables with a single column. Then we compute the intersection of these tables, which is again a table with a single column. Finally, we put this again into an array. I visualize this as turning the arrays around two times by 90 degrees.
Intermediate Result
The first week of Advent of SQL Code was fun and I somehow did not expect to get this far without resorting to plpgsql. I am definitely looking forward to the next week.